NLP analyzers for enhan(t) analytics module¶
Introduction enhan(t) NLP analyzers¶
As discussed in overview section enhan(t) analytics module enables you to extract helpful insights like engagement, sentiment and questions from your online video interactions. All of these tasks are accomplished by help of NLP analyzers on top of speech transcripts of video. Enhant analytics module is built as a service where a developer can add or remove any of these analyzers easily. To understand how we can add and remove analyzers let’s first look at Architecture of NLP analyzers:
Architecture NLP analyzer
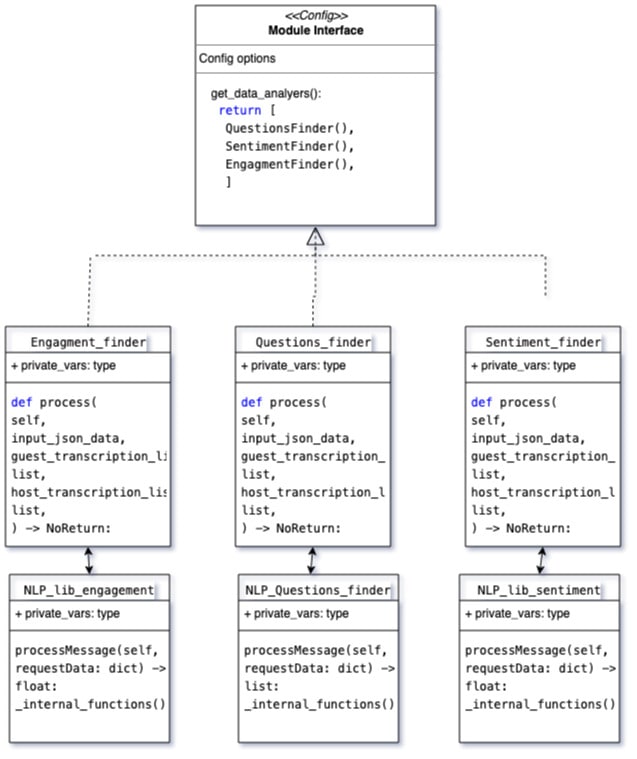
Take a look at above figure NLP Analyser Architecture, All of analytics is processed by our included cli application, cli application configures which analyzers to run on included transcriptions data using config module, in config module you can their is function you can get_data_analyers() where you can initialize your own custom nlp analyzer or remove any of the existing nlp analyzer.
Each of the NLP analyzers needs to follow this common input output syntax to help with modularity, hence each of them take input.json with host and guest side transcriptions in .srt format as input and results are written back in processed.json file.
Current NLP Analyzers¶
Currently insights like engagement, sentiment and questions are extracted from your online video interactions. Each of these features are provided by their respective modules in nlp_lib. We will briefly go through each one of them one by one.
Engagement Detection This module compares calculates engagement score for any conversation, Engagement score is a measure of how much is the guest or audience of your call is participating in call, So for any one sided call in which only host is speaking, engagement score is low, but in any call where host and guest both sides are equally speaking, engagement is high, to calculate engagement score, transcription data of both sides is used, for any given time window, engagement score is calculated by a heuristic of ratio of host vs guest side transcription. This analyzer is implemented with the help of `nltk library<https://www.nltk.org/>`_ and custom python implementation.
Question Detection This module is used for finding out what are the questions being asked in a given meeting, this is done by training a machine learning model (random forest) trained on nps_chat data which can classify whether a sentence is a question or not. This analyzer is implemented with the help of nltk library , scikit-learn and custom python implementation.
Sentiment Detection This module calculates sentiment score of each of the spoken sentence in meeting, In dashboard we can then show sentences which are outliers, means which have highly positive as well as negative sentiment scores. This analyzer is implemented with the help of pre-trained sentiment model from flair library and nltk library.
Adding your own nlp analyser¶
As shown in nlp Architecture diagram all of the NLP analyzers need to follow common interface which so if you need to add a additional nlp analyzers you need to implement same interface standard public interface. Which is
def process(
self,
input_json_data,
guest_transcription_list: list,
host_transcription_list: list,
) -> NoReturn:
This process function can call any of your own pre-processing logic, you can also create a new module implemented inside nlp_lib.
After implementing your own nlp analyser you can import it’s module inside cli/config.py file and add instance of your module class inside get_data_analyzers() function. e.g. currently in config.py get_data_analyers() function looks like this:
def get_data_analyzers() -> list:
"""
Returns the list of analyzers.
"""
# Add or remove analyzers here. All the analyzers will update the conversation JSON
return [
QuestionsFinder(),
SentimentFinder(),
EngagmentFinder(),
]
So if you want to add your custome nlp analyser than you can make a class for them with input output formatting similar to current nlp analyzers and then initialize object of the class in get_data_analyers function. e.g. if you analyzer is called my_custom_nlp_finder() than your new get_data_analyzers function will look like this:
def get_data_analyzers() -> list:
"""
Returns the list of analyzers.
"""
# Add or remove analyzers here. All the analyzers will update the conversation JSON
return [
QuestionsFinder(),
SentimentFinder(),
EngagmentFinder(),
my_custom_nlp_finder(),
]
Remove nlp analyser¶
Similarly if you need to remove any of the existing nlp analyzers you just need to remove their respective instance from get_data_analyzers function in cli/config file so if you want to remove let’s say engagement detection than you can delete it’s import statement
from engagment_finder import EngagmentFinder
and then can delete initialization code from get_data_analyzers function, so new get_data_analyzers will look like this:
def get_data_analyzers() -> list:
"""
Returns the list of analyzers.
"""
# Add or remove analyzers here. All the analyzers will update the conversation JSON
return [
QuestionsFinder(),
SentimentFinder(),
]